Agent 挽具解剖学
深度解析 Anthropic、OpenAI、Perplexity 和 LangChain 实际在构建什么。涵盖编排循环、工具、记忆、上下文管理,以及所有将无状态 LLM 转化为强大 Agent 的要素。
你搭建了一个聊天机器人。可能还用几个工具串起了 ReAct 循环。演示时运行良好。但当你尝试构建生产级系统时,轮子就掉了:模型忘了三步前做了什么,工具调用静默失败,上下文窗口里塞满了垃圾。
问题不在你的模型。在于你模型周围的一切。
LangChain 证明了这一点:他们只改变了包装 LLM 的基础设施(同样的模型、同样的权重),就在 TerminalBench 2.0 上从 30 名开外跃升至第 5 名。另一研究项目让 LLM 自行优化基础设施,达到 76.4% 的通过率,超越了手工设计的系统。
这个基础设施现在有了名字:Agent 挽具。
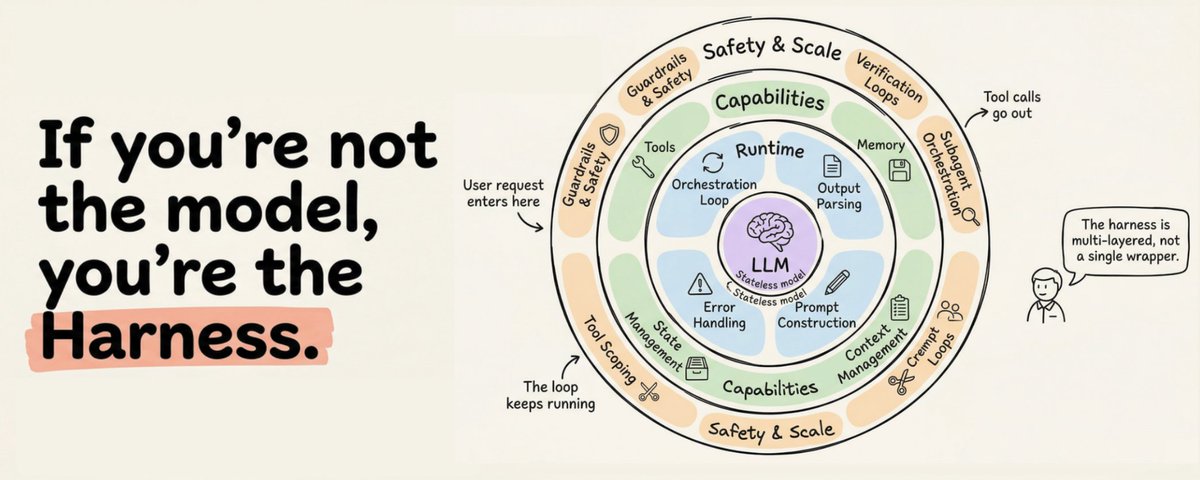
Agent 挽具是什么?
这个术语在 2026 年初才正式确立,但概念早已存在。挽具是包装 LLM 的完整软件基础设施:编排循环、工具、记忆、上下文管理、状态持久化、错误处理和安全防护。Anthropic 的 Claude Code 文档说得很简单:SDK 是"为 Claude Code 提供动力的 Agent 挽具"。OpenAI 的 Codex 团队采用同样的框架,明确将"Agent"和"挽具"这两个术语等同起来,指代让 LLM 有用的非模型基础设施。
我非常喜欢 LangChain 的 Vivek Trivedy 的经典公式:"如果你不是模型,你就是挽具。"
这里有个区别容易让人困惑。"Agent"是涌现出来的行为:面向目标的、使用工具的、自我纠正的实体,用户与之交互。挽具是产生这种行为的机器。当有人说"我构建了一个 Agent"时,他们的意思是构建了一个挽具并将其指向一个模型。

Beren Millidge 在他 2023 年的论文"作为自然语言计算机的脚手架式 LLM"中让这个类比精确化。原始 LLM 是没有内存、磁盘和 I/O 的 CPU。上下文窗口充当内存(快但有限)。外部数据库充当磁盘存储(大但慢)。工具集成充当设备驱动程序。挽具是操作系统。正如 Millidge 所写:"我们重新发明了冯·诺依曼架构",因为这对任何计算系统来说都是自然的抽象。
三层工程
模型周围有三层工程:
- 提示词工程精心设计模型接收的指令。
- 上下文工程管理模型看到什么以及何时看到。
- 挽具工程包含前两者,以及整个应用基础设施:工具编排、状态持久化、错误恢复、验证循环、安全执行和生命周期管理。
挽具不是提示词的包装器。它是使自主 Agent 行为成为可能的完整系统。
生产级挽具的 12 个组件
综合 Anthropic、OpenAI、LangChain 和更广泛的实践社区,一个生产级 Agent 挽具有 12 个不同的组件。让我们逐一了解。

1. 编排循环
这是心跳。它实现了思考-行动-观察(TAO)循环,也称为 ReAct 循环。循环运行:组装提示词,调用 LLM,解析输出,执行任何工具调用,反馈结果,重复直到完成。
从机制上讲,它通常只是一个 while 循环。复杂性在于循环管理的所有内容,而不是循环本身。Anthropic 将他们的运行时描述为"哑循环",所有智能都在模型中。挽具只是管理轮次。
2. 工具
工具是 Agent 的手。它们被定义为架构(名称、描述、参数类型),注入到 LLM 的上下文中,以便模型知道可用的内容。工具层处理注册、架构验证、参数提取、沙盒执行、结果捕获,以及将结果格式化为 LLM 可读的观察。
Claude Code 提供六个类别的工具:文件操作、搜索、执行、Web 访问、代码智能和子 Agent 生成。OpenAI 的 Agents SDK 支持函数工具(通过 @function_tool)、托管工具(WebSearch、CodeInterpreter、FileSearch)和 MCP 服务器工具。
3. 记忆
记忆在多个时间尺度上运行。短期记忆是单个会话内的对话历史。长期记忆跨会话持久化:Anthropic 使用 CLAUDE.md 项目文件和自动生成的 MEMORY.md 文件;LangGraph 使用按命名空间组织的 JSON 存储;OpenAI 支持由 SQLite 或 Redis 支持的会话。
Claude Code 实现了三层层次结构:轻量级索引(每个条目约 150 个字符,始终加载)、按需拉入的详细主题文件、以及仅通过搜索访问的原始转录本。一个关键设计原则:Agent 将自己的记忆视为"提示",并在行动前根据实际状态进行验证。
4. 上下文管理
这是许多 Agent 静默失败的地方。核心问题是上下文腐烂:当关键内容落在中间窗口位置时,模型性能下降 30% 以上(Chroma 研究,Stanford 的"迷失在中间"发现证实了这一点)。即使是百万 token 的窗口,随着上下文的增长,指令遵循能力也会下降。
生产级策略包括:
- 压缩:接近限制时总结对话历史(Claude Code 保留架构决策和未解决的错误,同时丢弃冗余的工具输出)
- 观察屏蔽:JetBrains 的 Junie 隐藏旧工具输出,同时保持工具调用可见
- 即时检索:维护轻量级标识符并动态加载数据(Claude Code 使用 grep、glob、head、tail 而不是加载完整文件)
- 子 Agent 委托:每个子 Agent 广泛探索但只返回 1,000 到 2,000 token 的压缩摘要
Anthropic 的上下文工程指南陈述了目标:找到能够最大化期望结果可能性的最小的高信号 token 集。
5. 提示词构建
这组装了模型在每个步骤实际看到的内容。它是分层的:系统提示词、工具定义、记忆文件、对话历史和当前用户消息。
OpenAI 的 Codex 使用严格的优先级堆栈:服务器控制的系统消息(最高优先级)、工具定义、开发者指令、用户指令(级联 AGENTS.md 文件,32 KiB 限制),然后是对话历史。
6. 输出解析
现代挽具依赖于原生工具调用,模型返回结构化的 tool_calls 对象,而不是必须解析的自由文本。挽具检查:有工具调用吗?执行它们并循环。没有工具调用?那是最终答案。
对于结构化输出,OpenAI 和 LangChain 都支持通过 Pydantic 模型的架构约束响应。传统方法如 RetryWithErrorOutputParser(将原始提示词、失败的完成和解析错误反馈给模型)仍可用于边缘情况。
7. 状态管理
LangGraph 将状态建模为通过图节点流动的类型化字典,使用 reducer 合并更新。检查点发生在超步边界,允许中断后恢复和时间旅行调试。OpenAI 提供四种互斥策略:应用内存、SDK 会话、服务器端对话 API 或轻量级 previous_response_id 链接。Claude Code 采取不同的方法:git 提交作为检查点,进度文件作为结构化便签本。
8. 错误处理
这很重要:一个每步成功率 99% 的 10 步过程,端到端成功率仍然只有约 90.4%。错误快速复合。
LangGraph 区分四种错误类型:瞬态(带退避重试)、LLM 可恢复(作为 ToolMessage 返回错误以便模型调整)、用户可修复(中断以等待人工输入)和意外(冒泡以供调试)。Anthropic 在工具处理程序中捕获失败并将它们作为错误结果返回以保持循环运行。Stripe 的生产级挽具将重试尝试限制为两次。
9. 防护栏和安全
OpenAI 的 SDK 实现了三个级别:输入防护栏(在第一个 Agent 上运行)、输出防护栏(在最终输出上运行)和工具防护栏(在每次工具调用上运行)。"触发线"机制在触发时立即停止 Agent。
Anthropic 在架构上将权限执行与模型推理分离。模型决定尝试什么;工具系统决定允许什么。Claude Code 独立控制约 40 个离散工具功能,分三个阶段:项目加载时建立信任、每次工具调用前检查权限、高风险操作需要明确用户确认。
10. 验证循环
这区分了玩具演示和生产级 Agent。Anthropic 推荐三种方法:基于规则的反馈(测试、linter、类型检查器)、视觉反馈(通过 Playwright 截图用于 UI 任务)和 LLM 作为评判者(单独的子 Agent 评估输出)。
Claude Code 的创建者 Boris Cherny 指出,给模型一种验证其工作的方法可将质量提高 2 到 3 倍。
11. 子 Agent 编排
Claude Code 支持三种执行模型:Fork(父上下文的字节相同副本)、Teammate(带有基于文件邮箱通信的独立终端窗格)和 Worktree(自己的 git 工作树,每个 Agent 隔离分支)。OpenAI 的 SDK 支持 Agent 即工具(专家处理有界子任务)和切换(专家完全接管)。LangGraph 将子 Agent 实现为嵌套状态图。
循环运行:逐步演练
现在你了解了组件,让我们追踪它们如何在单个循环中协同工作。
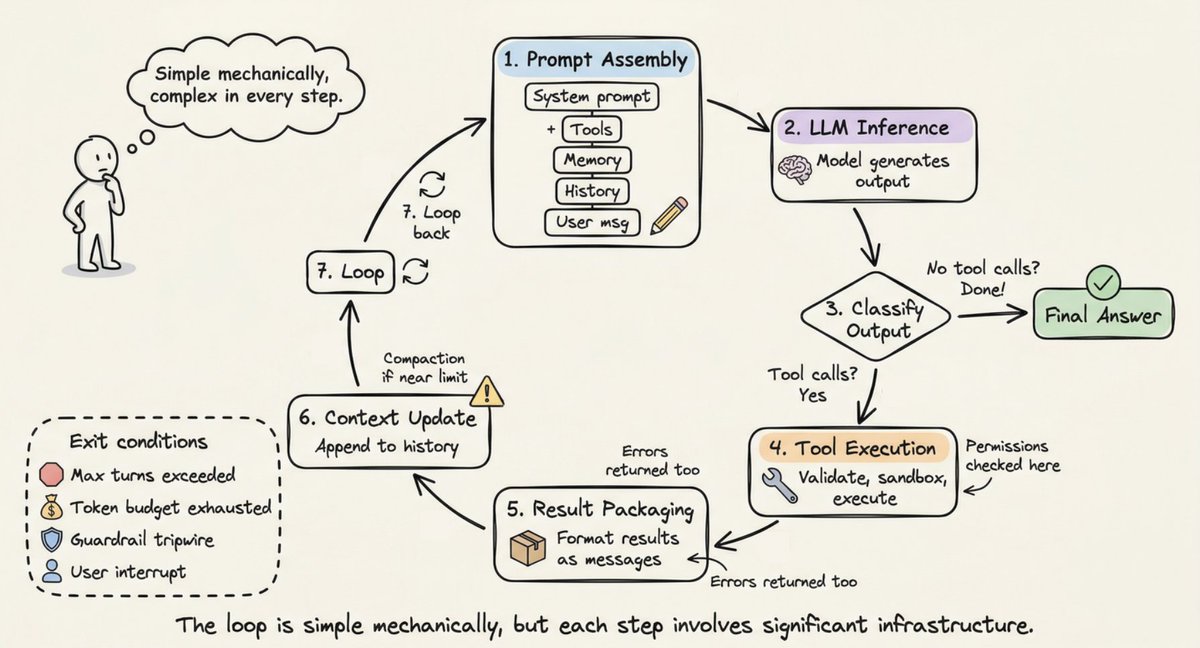
步骤 1(提示词组装):挽具构建完整输入:系统提示词 + 工具架构 + 记忆文件 + 对话历史 + 当前用户消息。重要的上下文被定位在提示词的开头和结尾("迷失在中间"发现)。
步骤 2(LLM 推理):组装的提示词进入模型 API。模型生成输出 token:文本、工具调用请求或两者皆有。
步骤 3(输出分类):如果模型生成了没有工具调用的文本,循环结束。如果它请求工具调用,继续执行。如果请求了切换,更新当前 Agent 并重新开始。
步骤 4(工具执行):对于每个工具调用,挽具验证参数、检查权限、在沙盒环境中执行并捕获结果。只读操作可以并发运行;变异操作串行运行。
步骤 5(结果打包):工具结果被格式化为 LLM 可读的消息。错误被捕获并作为错误结果返回,以便模型自我纠正。
步骤 6(上下文更新):结果被附加到对话历史。如果接近上下文窗口限制,挽具触发压缩。
步骤 7(循环):返回步骤 1。重复直到终止。
终止条件是分层的:模型生成没有工具调用的响应、超过最大轮次限制、token 预算耗尽、防护栏触发线触发、用户中断或返回安全拒绝。一个简单的问题可能需要 1 到 2 轮。复杂的重构任务可以在许多轮次中链接数十个工具调用。
对于跨越多个上下文窗口的长时间运行的任务,Anthropic 开发了一种两阶段的"Ralph 循环"模式:初始化 Agent 设置环境(初始化脚本、进度文件、功能列表、初始 git 提交),然后每个后续会话中的编码 Agent 读取 git 日志和进度文件以定位自己,选择最高优先级的未完成功能,处理它,提交并写入摘要。文件系统在上下文窗口之间提供连续性。
真实框架如何实现这一模式
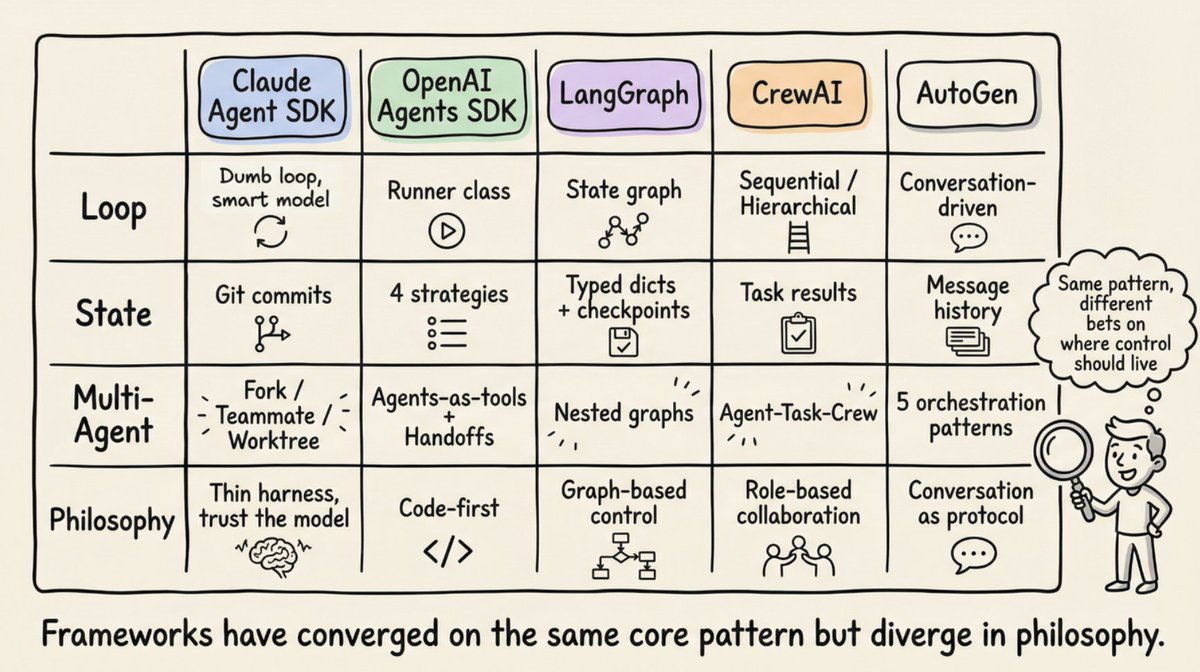
Anthropic 的 Claude Agent SDK 通过单个 query() 函数暴露挽具,该函数创建 Agent 循环并返回流式消息的异步迭代器。运行时是"哑循环"。所有智能都在模型中。Claude Code 使用 Gather-Act-Verify 循环:收集上下文(搜索文件、读取代码)、采取行动(编辑文件、运行命令)、验证结果(运行测试、检查输出)、重复。
OpenAI 的 Agents SDK 通过 Runner 类实现挽具,具有三种模式:异步、同步和流式。SDK 是"代码优先":工作流逻辑以原生 Python 表达,而不是图 DSL。Codex 挽具通过三层架构扩展了这一点:Codex Core(Agent 代码 + 运行时)、应用服务器(双向 JSON-RPC API)和客户端表面(CLI、VS Code、Web 应用)。所有表面共享相同的挽具,这就是为什么"Codex 模型在 Codex 表面上感觉比通用聊天窗口更好"。
LangGraph 将挽具建模为显式状态图。两个节点通过条件边连接:如果存在工具调用,路由到 tool_node;如果不存在,路由到 END。LangGraph 从 LangChain 的 AgentExecutor 演变而来,后者在 v0.2 中被弃用,因为它很难扩展且缺乏多 Agent 支持。LangChain 的 Deep Agents 明确使用术语"Agent 挽具":内置工具、规划(write_todos 工具)、用于上下文管理的文件系统、子 Agent 生成和持久记忆。
CrewAI 实现了基于角色的多 Agent 架构:Agent(LLM 周围的挽具,由角色、目标、背景故事和工具定义)、Task(工作单位)和 Crew(Agent 集合)。CrewAI 的 Flows 层添加了"在重要地方具有智能的确定性主干",管理路由和验证,而 Crew 处理自主协作。
AutoGen(演变为 Microsoft Agent Framework)开创了对话驱动的编排。它的三层架构支持五种编排模式:顺序、并发(扇出/扇入)、群聊、切换和磁控(管理 Agent 维护协调专家的动态任务分类账)。
脚手架隐喻
脚手架隐喻不是装饰性的。它是精确的。建筑脚手架是临时基础设施,使工人能够建造他们无法到达的结构。它不做建造工作。但没有它,工人无法到达上层。

关键见解:脚手架在建筑物完成后被移除。 随着模型的改进,挽具复杂性应该降低。Manus 在六个月内重建了五次,每次重写都移除了复杂性。复杂的工具定义变成了通用的 shell 执行。"管理 Agent"变成了简单的结构化切换。
这指向共同进化原则:模型现在在循环中使用特定挽具进行后期训练。Claude Code 的模型学会了使用它训练的特定挽具。更改工具实现可能会降低性能,因为这种紧密耦合。
挽具设计的"未来验证测试":如果性能随着更强大的模型扩展而无需增加挽具复杂性,那么设计是合理的。

定义每个挽具的七个决策
每个挽具架构师都面临七个选择:

单 Agent vs 多 Agent。 Anthropic 和 OpenAI 都说:首先最大化单个 Agent。多 Agent 系统增加开销(路由的额外 LLM 调用、切换期间的上下文丢失)。仅当工具负载超过约 10 个重叠工具或存在明显分离的任务域时才拆分。
ReAct vs 规划-执行。 ReAct 在每一步交错推理和行动(灵活但每步成本更高)。规划-执行将规划与执行分离。LLMCompiler 报告比顺序 ReAct 快 3.6 倍。
上下文窗口管理策略。 五种生产级方法:基于时间的清除、对话总结、观察屏蔽、结构化笔记和子 Agent 委托。ACON 研究表明,通过优先考虑推理跟踪而不是原始工具输出,token 减少 26% 至 54%,同时保持 95% 以上的准确性。
验证循环设计。 计算验证(测试、linter)提供确定性基本事实。推理验证(LLM 作为评判者)捕获语义问题但增加延迟。Martin Fowler 的 Thoughtworks 团队将其框架化为指南(前馈、行动前引导)与传感器(反馈、行动后观察)。
权限和安全架构。 宽松(快速但有风险,自动批准大多数操作)与限制性(安全但缓慢,每次操作都需要批准)。选择取决于部署上下文。
工具范围策略。 更多工具通常意味着更差的性能。Vercel 从 v0 中移除了 80% 的工具 并获得了更好的结果。Claude Code 通过延迟加载实现 95% 的上下文减少。原则:暴露当前步骤所需的最小工具集。
挽具厚度。 挽具中有多少逻辑与模型中有多少逻辑。Anthropic 赌薄挽具和模型改进。基于图的框架赌显式控制。Anthropic 定期从 Claude Code 的挽具中删除规划步骤,因为新模型版本内化了该能力。
挽具就是产品
两个使用相同模型的产品可能仅基于挽具设计就有截然不同的性能。TerminalBench 证据很清楚:仅更改挽具就将 Agent 移动了 20 多个排名位置。
挽具不是一个已解决的问题或商品层。它是困难工程所在的地方:将上下文作为稀缺资源管理、设计在错误复合之前捕获失败的验证循环、构建提供连续性而不产生幻觉的记忆系统,以及做出关于构建多少脚手架与留给模型多少的架构决策。
该领域正随着模型的改进向更薄的挽具迈进。但挽具本身不会消失。即使是最强大的模型也需要某种东西来管理其上下文窗口、执行其工具调用、持久化其状态并验证其工作。
下次你的 Agent 失败时,不要责怪模型。看看挽具。
就这样!
如果你喜欢阅读这篇文章:
找到我 → [@akshay_pachaar](https://x.com/@akshay_pachaar)
每天,我分享关于 AI、机器学习和氛围编码最佳实践的教程和见解。